Insurance Filings: The Overlooked Dataset That Drives Competitive Advantage
Insurance carriers submit 500,000+ regulatory filings annually—but most can't analyze them. Learn why Agentic AI is the key to unlocking competitive intelligence hidden in plain sight.


By Abdul Mohammed, Director of Product Marketing, ZestyAI
Every year, carriers and filers submit hundreds of thousands of rate, rule, and form transactions to state insurance departments (DOIs), many through SERFF. In 2023 alone, SERFF processed 517,571 transactions (NAIC SERFF, reported 2025). These filings are the DNA of the insurance market: the definitive record of how competitors set rates, where they plan to expand, and where they get approval for new ideas or pull back.
Even though much of this information is publicly available in many jurisdictions, with different rules for access and confidentiality, most carriers still miss out on the competitive signals hiding in plain sight.
Key takeaways
- Regulatory filings are a strategic dataset, not just compliance paperwork. They reveal competitor intent and market shifts.
- “Public” does not mean “easy to analyze.” Filings are often massive, cross-referenced, and inconsistently structured, making manual review at scale impossible.
- The winning approach is a filing intelligence stack. Success requires filing data tracked across amendments and effective dates, structured parsing, deterministic calculation, and precise citations.
How Filings Got So Complicated
From 1945 to The Modern Filing Ecosystem
The story begins with the McCarran-Ferguson Act of 1945, which gave states the power to regulate insurance rather than the federal government. As a result, requirements differ by state, making rates, rules, and forms complicated across jurisdictions.
In 1998, the National Association of Insurance Commissioners (NAIC) introduced SERFF (System for Electronic Rate and Form Filings), developed in collaboration with regulators and industry to digitize rate and form submissions. While it successfully moved filings online, the underlying complexity of the content remained.
Since then, the volume and complexity of filings have exploded. Our analysis of SERFF filing packages shows that the largest homeowners’ rate filing now exceeds 300,000 pages, including attachments, exhibits, and correspondence. In our data, the biggest package grew from 38,102 pages in 2009 to 346,064 pages in 2024.
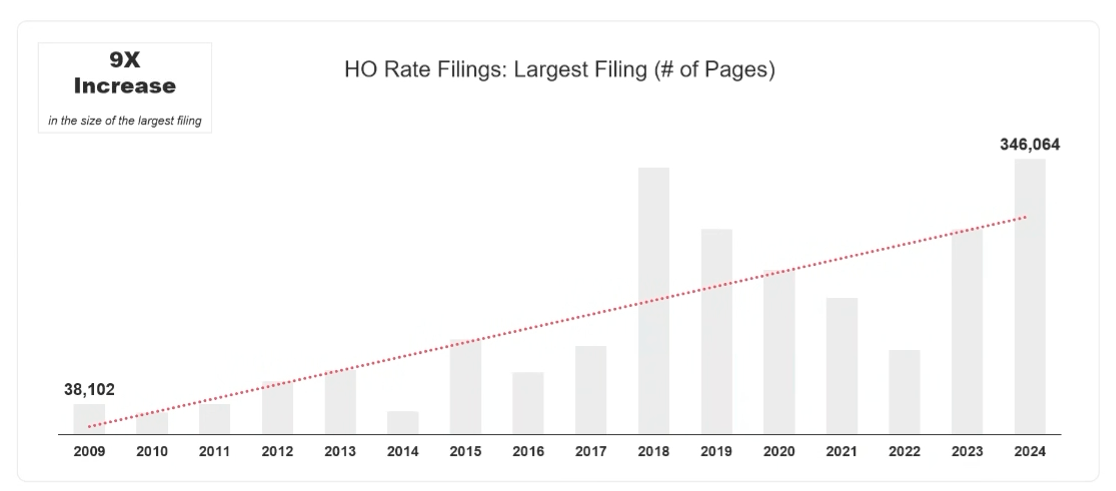
Page counts reflect the total number of PDF pages across all documents attached to the filing package, including exhibits, attachments, and objection/response correspondence.
Why Public Filings Remain Inaccessible for Analysis
A public filing is not always easy to access or understand. Carriers know that regulators, consumers, and competitors will review their filings, so the resulting documents are often dense, cross-referenced, and hard to piece together. If you have ever tried to reverse engineer a competitor rate change, you have probably faced these challenges:
The Trade Secret Exception
Some carriers request confidential treatment for specific elements of a filing that may qualify as trade secrets under state rules, such as granular territorial data or specific model inputs. When those sections are redacted or withheld, you lose visibility into important details even though the overall filing is public, and the level of protection varies by jurisdiction.
"When a Product Filing contains Trade Secret information, the Product Filer may identify those portions of the Product Filing, including correspondence with the Compact Office, that contain Trade Secret and seek to protect their disclosure."
Interstate Insurance Product Regulation Commission, FIN 2024-1
The Reference Maze
Sometimes, instead of putting all rate information in one document, a filing will reference several other filings across multiple years. To fully understand the change, an analyst has to track down and reconcile multiple historical filings, creating a confusing trail of "breadcrumbs" that is almost impossible to follow manually.
The PDF Image Trap
Many carriers submit rate tables as scanned images in PDFs instead of machine-readable text. While human eyes can read these tables, most data tools and basic OCR software treat them as pictures, so the information cannot be easily searched, filtered, or analyzed at scale.
The Objection and Response Trail
Often, the most valuable intelligence isn't in the initial filing, but in the "Objection and Response" exchanges between the carrier and the state regulator. These discussions can reveal rationale, supporting evidence, and the boundaries regulators will accept. However, this material is often spread across multiple attachments and correspondence, making it easy to miss critical insights without a structured way to collect and review them.
Non-Standard Nomenclature
There is no universal dictionary for insurance variables. One carrier might call the roof age factor “rf_yr_mod”, while another uses “const_age_rel”. Without a way to normalize these labels, mapping equivalent factors across carriers becomes manual work, making benchmarking slow, error-prone, and difficult to repeat.
Why General Purpose LLMs Often Struggle Here
We are in the age of Generative AI, so the natural question is: "Why not just upload these PDFs into a tool like ChatGPT or Gemini and ask questions?"
You can upload filing PDFs to ChatGPT or Gemini, and you may get a helpful summary. But insurance filing work is not “writing assistance.” It is a precision workflow in which small mistakes lead to incorrect conclusions. General-purpose LLMs are built to generate plausible text from the input you give them, not to reliably preserve filing structure, track versions, run exact calculations, and produce audit-ready citations.
The following are the top reasons why general LLMs often struggle in the inusrance domain:
1. The Math Problem
Insurance filings require exact math and exact linkage across tables, factors, relativities, and formulas. LLMs are probabilistic; they predict likely answers rather than performing exact calculations. If you ask an LLM to calculate a 3.5% rate increase over three years using a specific table, it may give a confident answer that is still wrong. In insurance, even a 0.01% mistake can mean millions in lost premium. As actuarial researchers noted in a 2024 paper from Cambridge University Press, “while LLMs can explain concepts, they often provide inaccurate or incorrect mathematical facts, sometimes in subtle ways.”
2. Structure Blindness
LLMs are mostly trained on regular text, such as books and articles. They are not skilled at understanding tables, following footnotes, or applying formulas consistently across multi-part exhibits, especially when documents are scanned or formatted inconsistently. A standard LLM treats a table as plain text and often fails to understand how the cells are logically and mathematically connected.
3. Context Window Overload
State filings are often longer than what standard LLMs can handle. If you give a model a 2,000-page document, it may lose track of what appeared earlier in the filing and still try to answer questions as if it remembered everything. This can cause the AI to make up numbers (hallucinate) to fill in missing information.
What a Modern Filing Intelligence Approach Looks Like
The industry does not need a better chatbot. It requires a filing intelligence stack that combines structured data, deterministic computation, and auditable reasoning.
Below are the key steps in building this intelligence stack:
Build a clean, versioned filing archive
Ingest filings continuously and preserve them with consistent metadata such as state, carrier, line, status, effective date, and relationships to related submissions. This creates a single, reliable system of record for all filing history.
Parse filings into insurance native components
Break filings into rates, rules, forms, exhibits, objections, and responses. Store rating tables, factors, and hierarchies as structured data instead of plain text, so they can be queried and reused.
Pair language with deterministic calculation
Use deterministic engines for calculations and rate reconstruction, then use language models to explain the results, clarify their meaning, and support structured analysis. The math engine produces the numbers; the LLM explains what they mean.
Make everything traceable
Every conclusion should link back to the exact filing section it came from. This traceability is what turns AI output into something regulators, actuaries, and executives can trust and defend.
The Future Belongs to the Agile
The number of filings and their sizes keep growing. As climate risk reshapes markets, rate reviews and underwriting changes will happen more often. The carriers who succeed will be those who treat regulatory filings as a source of strategic insight rather than a compliance burden.
Those who don’t will pay the price. Without visibility into how competitors are changing rates, rules, and eligibility in near-real time, carriers slip out of sync with the market, underwriting yesterday’s risk at today’s loss costs. That gap is where adverse selection takes hold.
Having access to filings is not enough to gain an edge. The real advantage comes from understanding them quickly and accurately, in a way that can be repeated across teams and product lines. To do this well, you need systems built for the job, not just a general-purpose model. This is where a purpose-built filing intelligence stack changes what is possible.
